2024年,大模型浪潮逐渐迈入了应用深化与广泛落地的关键阶段,集成了生成式AI技术的新产品以多种形式进入日常生活,成为工作、创作和娱乐的重要助手。不过,新AI技术与各行业深入融合的同时,也引发了数据安全、版权归属、伦理挑战等一系列担忧。
12月18日下午,由南都数字经济治理研究中心联合清华大学智能法治研究院主办的第八届啄木鸟数据治理论坛在北京举行,来自学术界、法律界、技术机构和企业等领域的专家学者围绕“AI应用落地提速,如何向善治理”主题展开探讨。会上,南都数字经济治理研究中心发布了《生成式AI用户风险感知和信息披露透明度测评报告(2024)》。
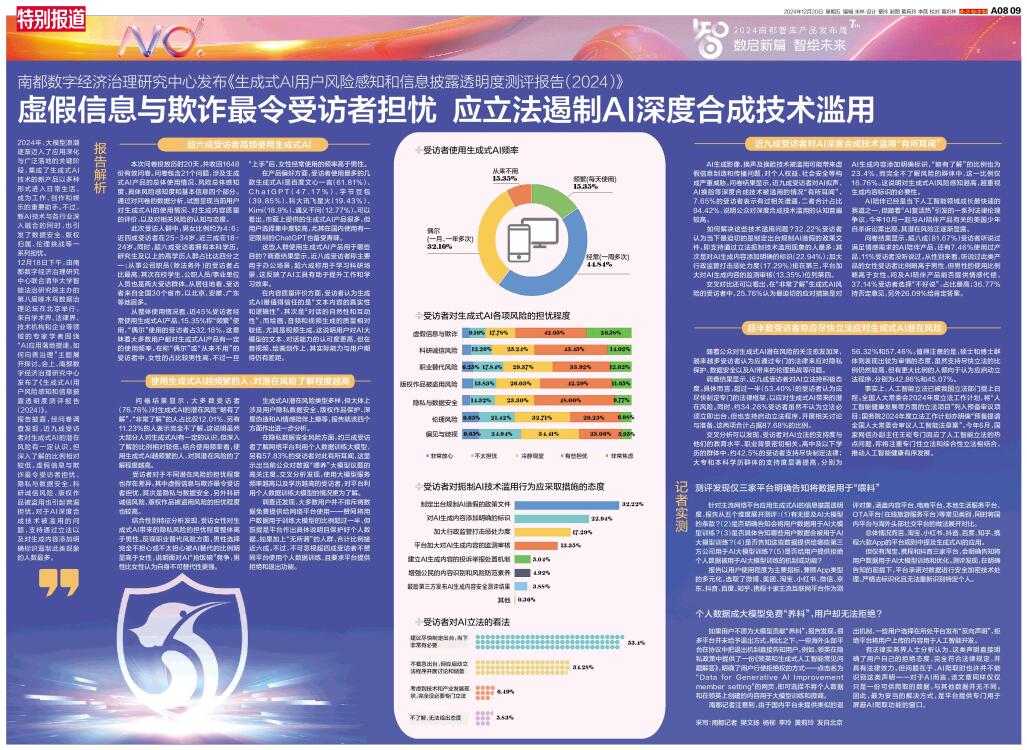
报告披露,经问卷调查发现,近九成受访者对生成式AI的潜在风险有一定认识,但深入了解的比例相对较低。虚假信息与欺诈最令受访者担忧,隐私与数据安全、科研诚信风险、版权作品被盗用也引起普遍担忧。对于AI深度合成技术被滥用的问题,支持通过立法以及对生成内容添加明确标识遏制此类现象的人数最多。
报告解析
超六成受访者高频使用生成式AI
本次问卷投放历时20天,共收回1648份有效问卷。问卷包含21个问题,涉及生成式AI产品的总体使用情况、风险总体感知度、具体风险感知度和基本信息四个部分。通过对问卷的数据分析,试图呈现当前用户对生成式AI的使用情况、对生成内容质量的评价,以及对相关风险的认知与态度。
此次受访人群中,男女比例约为4:6;近四成受访者在25-34岁,近三成在18-24岁。同时,超六成受访者拥有本科学历,研究生及以上的高学历人群占比达四分之一;从事公司职员(除法务外)的受访者占比最高,其次在校学生、公职人员/事业单位人员也是两大受访群体。从居住地看,受访者来自全国30个省市,以北京、安徽、广东等地居多。
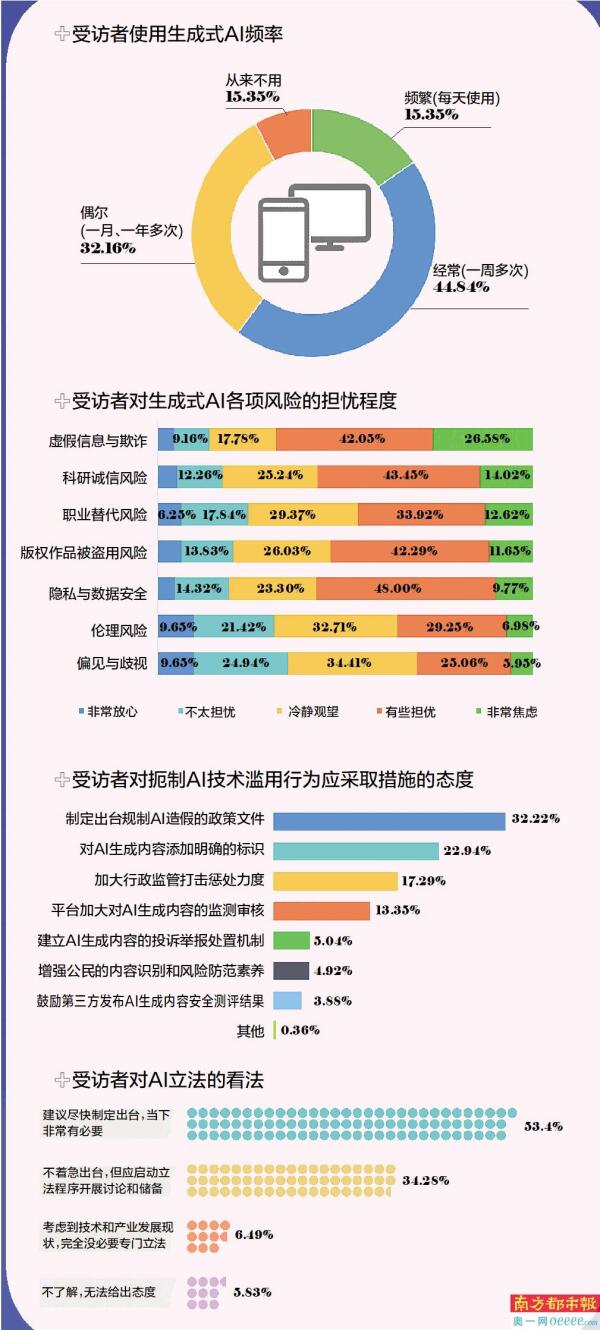
从整体使用情况看,近45%受访者经常使用生成式AI产品,15.35%称“频繁”使用,“偶尔”使用的受访者占32.16%,这意味着大多数用户都对生成式AI产品有一定的使用频率。在称“偶尔”或“从来不用”的受访者中,女性的占比较男性高,不过一旦“上手”后,女性经常使用的频率高于男性。
在产品偏好方面,受访者使用最多的几款生成式AI是百度文心一言(61.81%)、ChatGPT(47.17%)、字节豆包(39.85%)、科大讯飞星火(19.43%)、Kimi(18.9%)、通义千问(12.77%)。可以看出,市面上提供的生成式AI产品很多,但用户选择集中度较高,尤其在国内使用有一定限制的ChatGPT也备受青睐。
这些人群使用生成式AI产品用于哪些目的?调查结果显示,近八成受访者称主要用于办公场景,超六成称用于学习科研场景,这反映了AI工具有助于提升工作和学习效率。
在内容质量评价方面,受访者认为生成式AI最值得信任的是“文本内容的真实性和逻辑性”,其次是“对话的自然性和互动性”,而绘画、音频和视频生成的质量相对较低,尤其是视频生成。这说明用户对AI大模型的文本、对话能力的认可度更高,但在音视频、绘画创作上,其实际能力与用户期待仍有差距。
使用生成式AI越频繁的人,对潜在风险了解程度越高
问卷结果显示,大多数受访者(76.76%)对生成式AI的潜在风险“略有了解”,“非常了解”的人占比仅12.01%,另有11.23%的人表示完全不了解。这说明虽然大部分人对生成式AI有一定的认识,但深入了解的比例相对较低。结合使用频率看,使用生成式AI越频繁的人,对其潜在风险的了解程度越高。
受访者对于不同潜在风险的担忧程度也存在差异。其中虚假信息与欺诈最令受访者担忧,其次是隐私与数据安全,另外科研诚信风险、版权作品被盗用风险的担忧程度也较高。
结合性别特征分析发现,受访女性对生成式AI带来的隐私风险的担忧程度整体高于男性。反观职业替代风险方面,男性选择完全不担心或不太担心被AI替代的比例明显高于女性,说明面对AI“抢饭碗”竞争,男性比女性认为自身不可替代性更强。
生成式AI潜在风险类型多样,但大体上涉及用户隐私数据安全、版权作品保护、深度伪造和AI情感陪伴上瘾等,报告就该四个方面作出进一步分析。
在隐私数据安全风险方面,约三成受访者了解网络平台利用个人数据训练大模型,另有57.83%的受访者对此有所耳闻,这显示出当前公众对数据“喂养”大模型议题的高关注度。交叉分析发现,使用大模型服务频率越高以及学历越高的受访者,对平台利用个人数据训练大模型的情况更为了解。
调查还发现,大多数用户并不排斥将数据免费提供给网络平台使用——赞同将用户数据用于训练大模型的比例超过一半,但前提是平台作出具体说明且保护好个人数据。如果加上“无所谓”的人群,合计比例接近六成。不过,不可忽视超四成受访者不赞同平台使用个人数据训练,且要求平台提供拒绝和退出功能。
近九成受访者对AI深度合成技术滥用“有所耳闻”
AI生成影像、换声及换脸技术被滥用可能带来虚假信息制造和传播问题,对个人权益、社会安全等构成严重威胁。问卷结果显示,近九成受访者对AI拟声、AI换脸等深度合成技术被滥用的情况“有所耳闻”,7.65%的受访者表示有过相关遭遇,二者合计占比94.42%,说明公众对深度合成技术滥用的认知普遍较高。
如何解决这些技术滥用问题?32.22%受访者认为当下最迫切的是制定出台规制AI造假的政策文件,即支持通过立法扼制技术滥用现象的人最多;其次是对AI生成内容添加明确的标识(22.94%);加大行政监管打击惩处力度(17.29%)排在第三,平台加大对AI生成内容的监测审核(13.35%)位列第四。
交叉对比还可以看出,在“非常了解”生成式AI风险的受访者中,25.76%认为最迫切的应对措施是对AI生成内容添加明确标识,“略有了解”的比例也为23.4%,而完全不了解风险的群体中,这一比例仅16.76%。这说明对生成式AI风险感知越高,越重视生成内容标识的必要性。
AI陪伴已经是当下人工智能领域成长最快速的赛道之一,但随着“AI复活热”引发的一系列法律伦理争议,今年10月一起与AI陪伴产品有关的美国少年自杀诉讼案出现,其潜在风险正逐渐显露。
问卷结果显示,超八成(81.67%)受访者听说过满足情感需求的AI陪伴产品,还有7.46%使用过产品,11%受访者没听说过。从性别来看,听说过此类产品的女性受访者比例略高于男性,但男性的使用比例略高于女性。问及AI陪伴产品能否提供情感代偿,37.14%受访者选择“不好说”,占比最高;36.77%持否定意见,另外26.09%给肯定答案。
超半数受访者称应尽快立法应对生成式AI潜在风险
随着公众对生成式AI潜在风险的关注愈发加深,越来越多受访者认为应通过专门的法律来应对隐私保护、数据安全以及AI带来的伦理挑战等问题。
调查结果显示,近九成受访者对AI立法持积极态度。具体而言,超过一半(53.40%)的受访者认为应尽快制定专门的法律框架,以应对生成式AI带来的潜在风险。同时,约34.28%受访者虽然不认为立法必须立即出台,但也支持启动立法程序,开展相关讨论与准备。这两项合计占据87.68%的比例。
交叉分析可以发现,受访者对AI立法的支持度与他们的教育水平、职业背景密切相关。高中及以下学历的群体中,约42.5%的受访者支持尽快制定法律;大专和本科学历群体的支持度显著提高,分别为56.32%和57.46%。值得注意的是,硕士和博士群体则表现出较为审慎的态度,虽然支持尽快立法的比例仍然较高,但有更大比例的人倾向于认为应启动立法程序,分别为42.86%和45.07%。
事实上,人工智能立法已被我国立法部门提上日程。全国人大常委会2024年度立法工作计划,将“人工智能健康发展等方面的立法项目”列入预备审议项目;国务院2024年度立法工作计划亦明确“预备提请全国人大常委会审议人工智能法草案”。今年6月,国家网信办副主任王崧专门回应了人工智能立法的热点问题,称将注重专门性立法和综合性立法相结合,推动人工智能健康有序发展。
记者实测
测评发现仅三家平台明确告知将数据用于“喂料”
针对主流网络平台应用生成式AI的信息披露透明度,报告从五个维度展开测评:(1)有无提及AI大模型的条款?(2)是否明确告知会将用户数据用于AI大模型训练?(3)是否具体告知哪些用户数据会被用于AI大模型训练?(4)是否告知这些数据提供给哪些第三方公司用于AI大模型训练?(5)是否给用户提供拒绝个人数据被用于AI大模型训练的机制或功能?
报告以用户使用程度为主要指标,兼顾App类型的多元化,选取了微博、美团、淘宝、小红书、微信、京东、抖音、百度、知乎、携程十家主流互联网平台作为测评对象,涵盖内容平台、电商平台、本地生活服务平台、OTA平台(在线旅游服务平台)等常见类别,同时将国内平台与海外头部社交平台的做法展开对比。
总体情况而言,淘宝、小红书、抖音、百度、知乎、携程六款App的平台规则中提及生成式AI的应用。
但仅有淘宝、携程和抖音三家平台,会明确告知将用户数据用于AI大模型训练和优化。测评发现,在明确告知的前提下,平台承诺对数据进行安全加密技术处理、严格去标识化且无法重新识别特定个人。
个人数据成大模型免费“养料”,用户却无法拒绝?
如果用户不愿为大模型贡献“养料”,报告发现,很多平台并未给予退出方式。相比之下,一些海外头部平台在协议中把退出机制直接告知用户。例如,领英在隐私政策中提供了一份《领英和生成式人工智能常见问题解答》,明确了用户行使拒绝权的方式——点击名为“Data for Generative AI Improvement member setting”的网页,即可选择不将个人数据和在领英上创建的内容用于大模型训练和微调。
南都记者注意到,由于国内平台未提供类似的退出机制,一些用户选择在所处平台发布“反向声明”,拒绝平台将用户上传的内容用于人工智能开发。
有法律实务界人士分析认为,这类声明直接明确了用户自己的拒绝态度,完全符合法律规定,并具有法律效力。但问题在于,AI爬取时也许并不能识别这类声明——对于AI而言,该文章同样仅仅只是一份可供爬取的数据,与其他数据并无不同。因此,最为妥当的解决方式,是平台提供专门用于屏蔽AI爬取功能的窗口。
采写:南都记者 樊文扬 杨柳 李玲 黄莉玲 发自北京
